How to Fine-Tune SmolVLM2 on a Custom Dataset
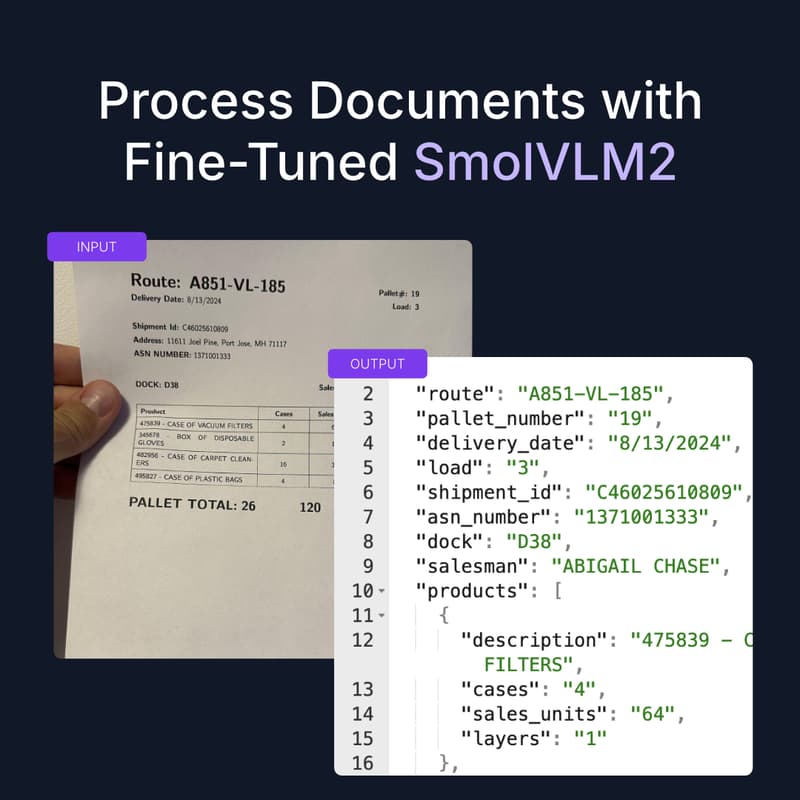
Do you have a large collection of documents — like shipping manifests, invoices, or engineering documents — and need to extract data from them using vision AI?
In this live session, we'll show you how to leverage SmolVLM2, a recently released multimodal model developed by Hugging Face, to fine-tune on a custom data for scanning documents and extracting useful data.
We'll guide you through the process, from preparing your dataset and training your model to deploying SmolVLM2 with custom data. Plus, we'll demonstrate how to create an automated workflow to transform extracted data from shipping manifests directly into a JSON format.
Every Thursday at 11am ET / 8am PT we dive into the world of computer vision and explore new tools, interesting projects, and tutorials. This webinar is open to everyone, we hope to see you there!
We'll also make time at the end for open Q&A.